ООО «ПС Авто Групп» — Официальный дистрибьютор TOTAL в РБ
Классификация моторных масел API для бензиновых двигателей
| SE *** | Бензиновые двигатели 1972. Те же требования к моторному маслу, что и для категории SD, но лучше защита двигателя. |
| SF *** | Бензиновые двигатели 1980. Те же требования, что и для категории SE, но улучшена защита от износа и окислительная стабильность. |
| SG *** | Бензиновые двигатели 1988. Те же требования, что и для категории SF, но лучше защита от износа, образования шлама и окисления масла. |
| SH *** | Бензиновые двигатели 1993. Те же требования, что и для категории SG, но вводится система лицензирования и записи результатов всех моторных тестов и формул с целью гарантии качества. Символ API, который свидетельствует о дейсвтительном соответствии уровню SH помещается на этикетки канистр. Символ API, который свидетельствует о дейсвтительном соответствии уровню SH помещается на этикетки канистр. |
| SJ | Бензиновые двигатели 1996. Те же требования, что и для категории SH (включая лицензию и систему сертификатов) с лучшей защитой от окисления масла при высоких температурах и забивания катализатора. Начиная с 01/08/97, уровень SJ официально заменяет SH. |
| SL | Бензиновые двигатели 2001. Новые тесты на степень износа (Seq IVA), моющие свойства моторного масла (TEOST MHT4), окисление (Seq IIIF) и низкотемпературные отложения (Seq VG) для лучшей защиты двигателя и продления интервала замены масла. Стандарт SL заменил API SJ в середине 2001г. |
| SM | Бензиновые двигатели 2004. Улучшены общие свойства для максимально-расширенного интервала замены масла. Ужесточен тест на высокотемпературные отложения (TEOST), новый тест на окисление (Seq. IIIG). IIIG). |
| SN | Бензиновые двигатели 2010. Представлен в октябре 2010 г. Разработан для автомобилей 2011 года выпуска и более ранних. Улучшенная защита от высокотемпературных отложений на поршнях. Более жесткие требования к контролю сажи и совместимости с уплотнителями. |
*** устаревшие классификации, подобно APISA, APISB, APISC и APISD.
Классификация моторных масел API для 2-тактных двигателей
Классификация API для 2-тактных двигателей имеет четыре уровня: TA, TB, TC для наземных транспортных средств и TD для использования на лодочных 2-тактных двигателеях. Производители рассматривают данную класификацию моторных масел как устаревшую. Эстафету приняла японская спецификация JASO, признанная в среде профессионалов. Международная специяикация ISO базируется на данной японской спецификации, опубликованной в 1997г.
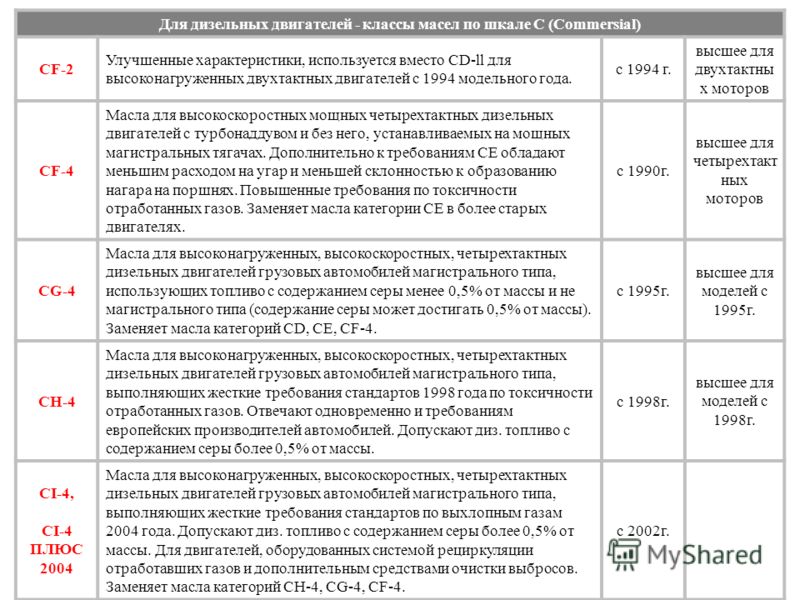
Спецификации по API для дизельных двигателей.
| CE * | «Требовательные» коммерческие дизельные двигатели (1987). Очень жесткие условия эксплуатации для нагруженных дизельных двигателей. Соответствует CD, усиленная защита от износа и высокотемпературных отложений, лучший контроль за окислением и расходом масла. Очень жесткие условия эксплуатации для нагруженных дизельных двигателей. Соответствует CD, усиленная защита от износа и высокотемпературных отложений, лучший контроль за окислением и расходом масла. |
| CF-4 * | «Требовательные» коммерческие дизельные двигатели (1991).Те же требования, что и для категории CE, но усиленная защита против отложений на поршнях и высокого расхода масла. |
| CF | Дизельные двигатели с непрямым впрыском (1994). Масла для строительной и карьерной техники, а также для двигателей, использующих дизельное топливо с высоким содержанием серы (>0.5%). Могут быть использованы вместо API CD. Иногда используются в дизельных двигателях для пассажирского транспорта. |
| CG-4 | Коммерческие дизельные двигатели, работающие в под тяжелыми нагрузками (развитие API CF-4, 1995). Масла для двигателей, соответствующих ограничениям по выхлопам в США 1994 г. (дизельное топливо с содержанием серы ≤ 0.05%). Могут быть использованы с дизельным топливом, содержащим серу в количестве до 0,5%). (дизельное топливо с содержанием серы ≤ 0.05%). Могут быть использованы с дизельным топливом, содержащим серу в количестве до 0,5%). |
| CH-4 | Дизельные двигатели под очень высокими нагрузками, удовлетворяющие стандартам по выхлопам США (1998). Масла, соответствующие требованиям США 1998г. для двигателей с пониженным уровнем выхлопов, специально разработаны для дизельного топлива с содержанием серы не более 0,5%. Особенно эффективны в борьбе с коррозией, износом, сажей и окислением. Высокая сдвиговая стабильность и устойчивость к вспениванию. Продлевают срок службы двигателей, эксплуатируемых в самых разнообразных условиях. Перекрывая требования предыдущих стандартов, данные масла достаточно гибко могут быть использованы в разнородных парках техники. |
| CI-4 | Дизельные двигатели под очень высокими нагрузками (2002). Масла для последних дизельных двигателей с пониженным выхлопом, перекрывает требования CH-4.
Новая версия, названная API CI-4 Plus была опубликована в 2004г. с целью улучшить совместимость с системами EGR |
| CJ-4 | Представлена в 2006г для 4-тактных высокоскоростных двигателей, удовлетворяющих требованиям к выхлопам 2007 года. Эти масла были разработаны для двигателей, оснащенных сажевыми фильтрами и рассчитанных на использование дизельного топлива с содержанием серы до 0,05%. Могут быть использованы вместо масел стандартов API CF-4, CG-4, CH-4, CI-4 и CI-4 Plus |
* устаревшие спецификации, ровно как и API CA, API CB, API CC and API CD. CF и CG-4.
CF и CG-4.
Классификация моторных масел API для 2-тактных дизельных двигателей.
| CD-II | 2-тактные дизельные двигатели, работающие в сложных условиях (1988). Улучшенная защита от износа и отложений. Удовлетворяет требованиям уровня CD. |
| CF-2 | 2-тактные дизельные двигатели, работающие в сложных условиях (1994). Более жесткие требования, чем API CD-II. Усиленная защита от износа поршневых колец и цилиндров. |
Классификация API трансмиссионных масел
API-GL-1
Минеральные трансмиссионные масла без присадок или с антиокислительными и противопенными присадками без противозадирных компонентов для применения, среди прочего, в коробках передач с ручным управлением с низкими удельными давлениями и скоростями скольжения. Цилиндрические, червячные и спирально-конические зубчатые передачи, работающие при низких скоростях и нагрузках.
API-GL-2
Червячные передачи, работающие в условиях GL-1 при низких скоростях и нагрузках, но с более высокими требованиями к антифрикционным свойствам. Могут содержать антифрикционный компонент.
API-GL-3
Трансмиссионные масла с высоким содержанием присадок с уровнем эксплуатационных свойств MIL-L-2105. Эти масла применяются предпочтительно в ступенчатых коробках передач и рулевых механизмах, в главных передачах и гипоидных передачах с малым смещением в автомобилях и безрельсовых транспортных средствах для перевозки грузов, пассажиров и для нетранспортных работ. Обладают лучшими противоизносными свойствами, чем GL-2.
API-GL-4
Трансмиссионные масла с высоким содержанием присадок с уровнем эксплуатационных свойств MIL-L-2105. Эти масла применяются предпочтительно в ступенчатых коробках передач и рулевых механизмах, в главных передачах и гипоидных передачах с малым смещением в автомобилях и безрельсовых транспортных средствах для перевозки грузов и пассажиров и для нетранспортных работ.
API-GL-5
Масла для гипоидных передач с уровнем эксплуатационных свойств MIL-L-2105 C/D. Эти масла предпочтительно применяются в передачах с гипоидными коническими зубатыми колесами и коническими колесами с круговыми зубьями для главной передачи в автомобилях и в карданных приводах мотоциклов и ступенчатых коробках передач мотоциклов. Специально для гипоидных передач с высоким смешением оси. Для самых тяжелых условий эксплуатации с ударной и знакопеременной нагрузкой.
Международная классификация масел API по уровням эксплуатационных свойств
AGA — Международная классификация масел API по уровням эксплуатационных свойств- Главная
- О компании
- Новости
- Автопробеги
- Вакансии
- Интересное видео
- Партнерство
- Дилер РФ
- Оптовые продажи
- Зарубежные партнеры
- Каталог продукции
- Торговые марки
- Экспертиза и обучение
- FAQ
- Колонка тех.
 эксперта
эксперта - Форум
- Обучение
- Подбор промывок
- Каталог 300 советов
- Где купить?
- АВТОМАГ
Международная классификация масел API по уровням эксплуатационных свойств
Первая классификация моторных масел по условиям применения и уровням эксплуатационных свойств была разработана американским институтом нефти (АРI) еще в 1947 году. Используя латинский алфавит, буквосочетание API правильно произносится «эй — пи — ай», но обычно говорят просто «апи». С тех пор она многократно изменялась и дополнялась, но принцип подразделения моторных масел на две категории сохранялся всегда.
- К категории «S» (Service — сервис) относятся масла, предназначенные для четырехтактных бензиновых двигателей легковых автомобилей, микроавтобусов, пикапов (на них в США выполняется максимум сервисного обслуживания).
- К категории «С» (Commercial — коммерческий) относятся масла, предназначенные для дизелей дорожно-строительной, сельскохозяйственной техники, автотранспорта, большегрузных тягачей (на чем «делают» коммерцию).

Уровни эксплуатационных свойств в классификации API обозначаются буквами латинского алфавита, стоящими за буквой «S» (для бензиновых ДВС) и за буквой «С» (для дизелей). Уровень эксплуатационных свойств возрастает по порядку латинского алфавита: А, В, С, D, E, F, G, H, J, L (буква I, стоящая в алфавите между Н и J, пропущена во избежание путаницы с похожей по написанию буквой J).
Классы масел для бензиновых двигателей (категория S)
- SL — для европейских и американских автомобилей выпуска с середины 2001 г.
- SJ — для европейских и американских автомобилей выпуска с конца 1996 г. до середины 2001 г.
- SH — для европейских и американских автомобилей 1993-96 г. выпуска и японских автомобилей с 1995 г. выпуска.
- SG — для европейских и американских автомобилей 1989-93 г. выпуска и японских автомобилей 1989-1995 г. выпуска.
- SF— для европейских и американских автомобилей 1980-89 г.
 выпуска и отечественных автомобилей.
выпуска и отечественных автомобилей.
Классы масел для дизельных двигателей (категория С)
- СН-4 — для высокофорсированных четырехтактных дизелей автомобилей выпуска после 1998 г., заменяют CF, CG.
- CG-4 — для высокофорсированных четырехтактных дизелей автомобилей выпуска после 1994 г.
- CF-2 — отвечающие требованиям для двухтактных дизелей транспортных средств. CF-4 — для высокофорсированных четырехтактных дизелей автомобилей выпуска до 1994 г.
- CF — для дизелей автомобилей выпуска до 1993-х.
Универсальные масла
Для обозначения универсальных масел используют двойную маркировку, например, API CF-4 / SG, API SH / CG-4 и т.п.
EC (ENERGY CONSERVING) — это обозначение применяется для энергосберегающих масел. Энергосберегающие масла отличаются малой вязкостью, легкотекучестью, минимальной испаряемостью.
Цифры при обозначении классов CF-4, CF-2, CG-4 дают информацию о соответствии класса к двухтактным или четырехтактным дизелям.
Поскольку работа автомобильного двухтактного ДВС характеризуется повышенной теплонапряженностью деталей, то масла для таких двигателей отличаются высокими противозадирными и противоизносными свойствами и небольшой зольностью. При тестировании масла на пригодность к применению на двухтактных дизелях, кроме лабораторных испытаний, методика API предусматривает стендовые испытания на полноразмерном двухтактном дизеле с турбо-наддувом. Устаревшие классы за ненадобностью сегодня исключены из классификации API. В настоящее время в США сертифицируют масла только с высшими уровнями эксплуатационных свойств.
Моторные масла, сертифицированные на соответствие тем или иным классам API, маркируются стандартным символом в виде двойного круга, в центре которого указаны классы вязкости по SAE (см. рис.1). На некоторых упаковках масел могут быть указаны уровни эксплуатационных свойств по API, но без стандартного символа с двойным кругом.
Это означает, что данное масло не проходило непосредственную сертификацию по классификации API, и классы API указаны по аналогии соответствия с другой системой классификации.
Тормозные жидкости
Назначение тормозной жидкости состоит в передаче энергии от главного тормозного цилиндра к колесным цилиндрам, которые прижимают тормозные накладки к тормозным дискам или барабанам.
Классификация пластичных смазок
Следует отметить, что не все нижеперечисленные классификации являются общепринятыми для отечественных и зарубежных производителей.
Международная классификация масел API по уровням эксплуатационных свойств
Первая классификация моторных масел по условиям применения и уровням эксплуатационных свойств была разработана американским институтом нефти (АРI) еще в 1947 году.
Напишите нам
Какая информация вас интересует? * Техническая информацияСотрудничество Приложить документ (не более 5 МБ)
Классификация API
| Бензиновые двигатели | |||
| SN |
Это последняя сервисная категория для автомобилей с бензиновыми двигателями, введена в октябре 2010г. |
||
| SM | Введена в ноябре 2004. Тенденции развития техники направлены на повышение их экологической безопасности, увеличение интервалов техобслуживания при сохранении надежности работы. Естественно, это вносит свои коррективы в качества смазывающих материалов. Следуя данным тенденциям, в ноябре 2004 года в классификации API появился класс на моторные масла для бензиновых двигателей — SM, предполагающий, по сравнению с SL, повышенные требования к смазывающим материалам относительно стойкости к окислению, защите от отложений, износа и т.д. С октября 2006 года пополнилась категория и для дизельных масел классом CJ-4. Следуя данным тенденциям, в ноябре 2004 года в классификации API появился класс на моторные масла для бензиновых двигателей — SM, предполагающий, по сравнению с SL, повышенные требования к смазывающим материалам относительно стойкости к окислению, защите от отложений, износа и т.д. С октября 2006 года пополнилась категория и для дизельных масел классом CJ-4. |
||
| SL | (Действующая). API планировал разрабатывать проект PS-06 как следующую категорию API SK, но один из поставщиков моторных масел в Корее использует сокращение «SK» как часть своего корпоративного имени. Для исключения возможной путаницы буква «К» будет пропущена для следующей категории «S». — стабильность энергосберегающих свойств; — пониженная летучесть; — удлиненные интервалы замены. |
c 2001 | |
| SJ | (Действующая). Категория утверждена 06.11.1995, лицензии стали выдаваться с 15.10.1996. Автомобильные масла данной категории предназначены для всех используемых в настоящее время бензиновых двигателей и полностью заменяют масла всех существовавших ранее категорий в более старых моделях двигателей. Максимальных уровень эксплуатационных свойств. Возможность сертификации по категории энергосбережения API SJ/EC. Категория утверждена 06.11.1995, лицензии стали выдаваться с 15.10.1996. Автомобильные масла данной категории предназначены для всех используемых в настоящее время бензиновых двигателей и полностью заменяют масла всех существовавших ранее категорий в более старых моделях двигателей. Максимальных уровень эксплуатационных свойств. Возможность сертификации по категории энергосбережения API SJ/EC. |
c 1996 | |
| SH | (Условно действующая). Лицензированная категория, утвержденная в 1992 году. На сегодняшний день категория является условно действующей и может быть сертифицирована только как дополнительная к категориям API C (например API AF-4/SH). По требованиям соответствует категории ILSAC GF-1, но без обязательного энергосбережения. Автомобильные масла данной категории предназначены для бензиновых двигателей моделей 1996 года и старше. При проведении сертификации на энергосбережение, в зависимости от степени экономии топлива присваивались категории API SH/EC и API SH/ECII.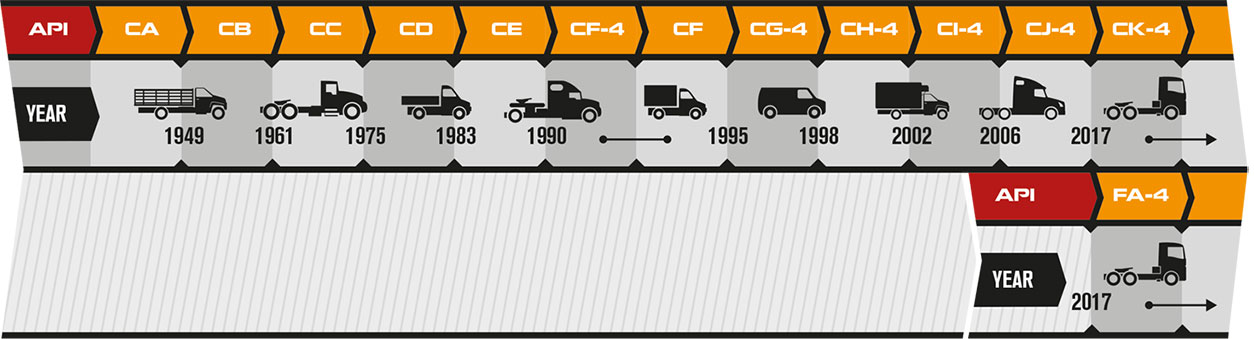 |
с 1993 | |
| SG | Лицензированная категория, утвержденная в 1988 году. Выдача лицензий прекращена в конце 1995 года. Автомобильные масла предназначены для двигателей моделей 1993 года и старше. Топливо — неэтилированный бензин с оксигенатами. Удовлетворяют требованиям, выдвигаемым к автомобильным маслам для дизельных двигателей категории API CC и API CD. Имеют более высокую термическую и противоокислительную стабильность, улучшенные противоизносные свойства, уменьшенную склонность к образованию отложений и шлама. Автомобильные масла API SG заменяют масла категорий API SF, SE, API SF/CC и API SE/CC. |
1989-1993 | |
| SF | Автомобильные масла данной категории предназначены для двигателей моделей 1988 года и старше. Топливо — этилированный бензин. Они имеют более эффективные, чем предыдущие категории, противоокислительные, противоизносные, антикоррозийные свойства и обладают меньшей склонностью к образованию высоко- и низкотемпературных отложений и шлака. Автомобильные масла API SF заменяют масла API SC, API SD и API SE в более старых двигателях. |
1981-1988 | |
| SE | Высокофорсированные двигатели, работающие в тяжелых условиях. | 1972-1980 | |
| SD | Среднефорсированные двигатели, работающие в тяжелых условиях. | 1968-1971 | |
| SC | Двигатели, работающие с повышенными нагрузками. | 1964-1967 | |
| SB | Двигатели, работающие при умеренных нагрузках, используется только по требованию производителя. | — | |
| SA | Двигатели, работающие в легких условиях, используется только по требованию производителя. | — | |
 Заменяет предыдущую сервисную категорию SM. Моторные масла, отвечающие API SN, могут использоваться в двигателях, которым предписаны категории API SM и более ранние категории S. Масла API SN улучшены по сравнению с API SM в областях окислительной стабильности и контроля отложений и шламов. Совместимо с топливами, содержащими этанол (вплоть до Е85, т.е. с топливами, содержащими до 85% биоэтанола). Масла, классифицируемые по API SN, приблизительно соответствовуют АСЕА С2, С3, С4, без поправки на высокотемпературную вязкость.
Заменяет предыдущую сервисную категорию SM. Моторные масла, отвечающие API SN, могут использоваться в двигателях, которым предписаны категории API SM и более ранние категории S. Масла API SN улучшены по сравнению с API SM в областях окислительной стабильности и контроля отложений и шламов. Совместимо с топливами, содержащими этанол (вплоть до Е85, т.е. с топливами, содержащими до 85% биоэтанола). Масла, классифицируемые по API SN, приблизительно соответствовуют АСЕА С2, С3, С4, без поправки на высокотемпературную вязкость.
| Дизельные двигатели | |||
| Класс | Описание и область применения | Годы выпуска автомобилей | Качественные показатели |
| CJ-4 | Введена в 2006. Для быстроходных четырёхтактных двигателей, проектируемых для удовлетворения норм по токсичности отработавших газов 2007 года на магистральных дорогах. Масла CJ-4 допускают использование топлива с содержанием серы вплоть до 500 ррт (0,05% от массы). Однако работа с топливом, в котором содержание серы превышает 15 ррт (0,0015% от массы), может сказаться на работоспособности систем очистки выхлопных газов и/или интервалах замены масла. Для быстроходных четырёхтактных двигателей, проектируемых для удовлетворения норм по токсичности отработавших газов 2007 года на магистральных дорогах. Масла CJ-4 допускают использование топлива с содержанием серы вплоть до 500 ррт (0,05% от массы). Однако работа с топливом, в котором содержание серы превышает 15 ррт (0,0015% от массы), может сказаться на работоспособности систем очистки выхлопных газов и/или интервалах замены масла.Масла CJ-4 рекомендованы для двигателей, оборудованных дизельными сажевыми фильтрами и другими системами обработки выхлопных газов. Масла со спецификацией CJ-4 превышают рабочие свойства CI-4, CI-4 Plus, CH-4, CG-4, CF-4 и могут применяться в двигателях, которым рекомендуются масла этих классов. |
с 2006 | — |
| СI-4 | Введена в 2002 году. Для быстроходных четырёхтактных двигателей, проектируемых для удовлетворения нормам по токсичности отработавших газов, осуществляемым в 2002 году. Масла СI-4 допускают использование топлива с содержание серы вплоть до 0,5% от массы, а также применяются в двигателях с системой рециркуляции отработанных газов (EGR). Заменяет CD, СЕ, CF-4, CG 4 и СН-4 масла. Масла СI-4 допускают использование топлива с содержание серы вплоть до 0,5% от массы, а также применяются в двигателях с системой рециркуляции отработанных газов (EGR). Заменяет CD, СЕ, CF-4, CG 4 и СН-4 масла.В 2004 году была введена дополнительная категория API CI-4 PLUS. Ужесточены требования к сажеобразованию, отложениям, вязкостным показателям, ограничение значения TBN. |
с 2002 | — |
| СH-4 | Введена в 1998 году. Для быстроходных четырёхтактных двигателей, удовлетворяющих требования по токсичности выхлопных газов, введенных в США с 1998 года. Масла СН-4 позволяют использовать топливо с содержанием серы вплоть до 0,5% от массы. Можно использовать вместо CD, СЕ, CF-4 и CG-4 масел. | с 1998 | — |
| СG-4 | Введена в 1995 году. Для двигателей быстроходной дизельной техники, работающей на топливе с содержанием серы менее чем 0,5%. Масла CG-4 для двигателей, выполняющих требования по токсичности отработанных газов, введенные в США с 1994 года. Заменяет масла CD, СЕ и CF-4 категорий. Масла CG-4 для двигателей, выполняющих требования по токсичности отработанных газов, введенные в США с 1994 года. Заменяет масла CD, СЕ и CF-4 категорий. |
с 1995 | высшее для моделей с 1995 г. |
| СF-4 | Введена в 1990 году. Для быстроходных четырехтактных дизельных двигателей с турбонаддувом и без него. Можно применять вместо CD и СЕ масел. | с 1990 | высшее для четырехтактных моторов |
| СF-2 | Введена в 1994 году. Улучшенные характеристики, используется вместо CD-II для двухтактных двигателей. | с 1994 | высшее для двухтактных моторов |
| CF | Введена в 1994 году. Масла для внедорожной техники, двигателей с разделительным впрыском, в том числе работающих на топливе с содержанием серы 0,5% от массы и выше. Заменяет масла CD. | с 1994 | — |
| CE | Высокофорсированные перспективные двигатели с высоким турбонаддувом, работающие в тяжелых условиях, может использоваться вместо масел классов CC и CD. |
с 1987 | высшее |
| CD | Класс масел для скоростных дизельных двигателей с турбонаддувом и высокой удельной мощностью, работающих на больших скоростях и при высоких давлениях и требующих повышенных противоиносных свойств и предотвращения образования нагара. | с 1955 | среднее |
| CC | Высокофорсированные двигатели (в том числе с умеренным наддувом), работающие в тяжелых условиях. | с 1961 | низкие |
| CB | Среднефорсированные двигатели без наддува, работающие при повышенных нагрузках на сернистом топливе. | 1949-1960 | — |
| CA | Двигатели, работающие при умеренных нагрузках на малосернистом топливе. | 1940-1950 | — |
| Дизельные и бензиновые двигатели |
Универсальные масла для бензиновых двигателей и дизелей имеют обозначения обеих категорий, например API SG/CD, API SJ/CF.
Классы дизельных масел подразделяются дополнительно для двухтактных (CD-2, CF-2) и четырехтактных дизелей (CF-4, CG-4, СН-4).
В настоящее время API сертифицирует моторные масла классов SJ, SL, CF, CF-2, CF-4, CG-4, СН-4. Масла остальных классов по API, отмененных в США, следует использовать, если они допущены производителями автомобилей.
Лучшие API-интерфейсы классификации текста — автоматическая организация данных
Вы можете выбирать между API-интерфейсами классификации текста с открытым исходным кодом и SaaS для подключения неструктурированного текста к инструментам ИИ. Библиотеки с открытым исходным кодом могут помочь разработчикам создавать гибкие и настраиваемые модели классификации текста, но их настройка требует времени.
API-интерфейсы SaaS для классификации текста, с другой стороны, намного проще и быстрее реализовать, требуют меньше ресурсов и меньше технических знаний.
Читайте дальше, чтобы узнать о некоторых из лучших API-интерфейсов с открытым исходным кодом и SaaS, которые вы можете использовать для классификации вашего текста.
- Лучшие API SaaS для классификации текста
- Лучшие библиотеки с открытым исходным кодом для классификации текста
Лучшие API классификации текста (SaaS и с открытым исходным кодом)
Лучшие API SaaS для классификации текста
Большинство этих инструментов предлагают пробные версии или предварительно обученные модели, чтобы вы могли проверить, подходят ли они для вашей бизнес-модели:
- MonkeyLearn
- Google Cloud NLP
- Aylien
- IBM Watson
- Meaning Cloud
- Lexalytics
- Amazon Comprehend
1. MonkeyLearn
MonkeyLearn — это удобная платформа машинного обучения, которая позволяет сразу погрузиться в классификацию текста с помощью предварительно обученных моделей. Одной из самых популярных моделей классификации текста является классификатор тональности, к которому можно сразу же подключиться через MonkeyLearn API.
Тест с собственным текстом
Отличные готовые функции CRM. Некоммерческие организации получают 10 лицензий бесплатно и скидки на дополнительную лицензию.
Некоммерческие организации получают 10 лицензий бесплатно и скидки на дополнительную лицензию.Результаты
Positive99.1%
Вы также можете легко создавать собственные классификаторы текста с помощью MonkeyLearn для получения более точных сведений и начать определять темы, настроения, намерения и многое другое. Всего за несколько шагов вы можете определить свои теги, обучить свою модель, используя свои собственные данные, и подключить ее через API всего несколькими строками кода.
Ознакомьтесь с ценами и планами.
2. Google Cloud NLP
Google Cloud NLP — это набор инструментов для анализа текста, помогающих находить ценные сведения в неструктурированных данных.
Используя Natural Language API, вы можете подключаться к мощным предварительно обученным моделям, предназначенным для получения общих результатов с высокой точностью для анализа тональности и классификации контента. Например, инструмент классификации контента позволяет классифицировать документы по более чем 700 категориям.
Если вам нужна модель классификации, адаптированная к конкретному варианту использования, вы можете использовать AutoML Natural Language, который позволяет создавать индивидуальные решения с использованием предварительно определенных категорий.
3. Aylien
Aylien — это платформа искусственного интеллекта, которая предлагает различные решения для анализа текста для бизнеса. С помощью API классификации текста вы можете автоматически находить темы в документах или на веб-сайтах.
API применяет две таксономии: одна использует 500 категорий для маркировки новостей и медиа-контента, а другая больше ориентирована на рекламу и позволяет компаниям отображать онлайн-рекламу в нужных местах.
4. IBM Watson
IBM Watson — это мультиоблачная платформа с набором инструментов искусственного интеллекта для классификации бизнес-данных. С помощью классификатора естественного языка разработчики могут создавать собственные модели классификации для поиска тем в данных. Вы можете обучить модель менее чем за 15 минут (знание машинного обучения не требуется) и легко интегрировать модели в свои приложения с помощью API.
Вы можете обучить модель менее чем за 15 минут (знание машинного обучения не требуется) и легко интегрировать модели в свои приложения с помощью API.
Watson также предоставляет встроенное решение для анализа текста под названием «Понимание естественного языка», которое можно использовать для поиска настроений, эмоций и категорий в тексте.
5. Meaning Cloud
Meaning Cloud предлагает набор облачных API для анализа текста. API классификации текста поставляется с рядом предопределенных категорий для автоматической сортировки данных (например, вы можете классифицировать новостной контент по более чем 1300 темам), или вы можете создавать собственные модели, используя свои собственные категории.
API анализа настроений, с другой стороны, помогает вам определять полярность и иронию в тексте на разных языках. Разработчики также могут настраивать это решение, определяя собственные словари, адаптированные к их предметной области.
6. Lexalytics
Lexalytics — это модульная платформа бизнес-аналитики, предлагающая различные решения для анализа текста. Semantria API позволяет выполнять категоризацию документов и анализ настроений с помощью обработки естественного языка и машинного обучения.
Semantria API позволяет выполнять категоризацию документов и анализ настроений с помощью обработки естественного языка и машинного обучения.
Модели поддерживают текст на разных языках и обладают широкими возможностями настройки: вы можете легко обучить их распознавать отраслевую лексику и настраивать различные параметры для получения лучших результатов.
7. Amazon Comprehend
Amazon Comprehend — это сервис NLP с набором API-интерфейсов, которые вы можете легко интегрировать в свои приложения. Вы найдете API для анализа тональности, определения языка и API пользовательской классификации, которые помогут вам создавать модели классификации текста, адаптированные к потребностям вашего бизнеса. Вам не нужны какие-либо знания в области машинного обучения или обширные навыки кодирования для создания пользовательской модели.
Верхние библиотеки с открытым исходным кодом для классификации текста
- Scikit-Learn
- Tensorflow
110
- Pytorch
- KERAS
1.
 SCIKIT-LEARN-LARN-LARN-LARN 77777777777777777777777777777777777777777777777777777777777777777777777777777. удобная библиотека машинного обучения для Python. Благодаря хорошо задокументированному API вы можете подключаться к различным алгоритмам классификации и создавать модели для таких задач, как обнаружение спама, распознавание изображений и классификация тем.
SCIKIT-LEARN-LARN-LARN-LARN 77777777777777777777777777777777777777777777777777777777777777777777777777777. удобная библиотека машинного обучения для Python. Благодаря хорошо задокументированному API вы можете подключаться к различным алгоритмам классификации и создавать модели для таких задач, как обнаружение спама, распознавание изображений и классификация тем.Это отличная библиотека для начинающих, которая хорошо работает в большинстве случаев.
2. Набор инструментов для работы с естественным языком (NLTK)
Обладая большим количеством ресурсов и алгоритмов, NLTK является одной из самых известных библиотек Python для анализа текста, особенно среди исследователей и студентов, желающих получить практический опыт.
Вы найдете несколько API-интерфейсов, которые можно использовать для классификации тем и анализа настроений, а также помеченные наборы данных, которые можно использовать для их обучения. Основным недостатком этой библиотеки является то, что она не обрабатывает данные в масштабе.
3. SpaCy
SpaCy — это библиотека Python для НЛП, которую хвалят за быстроту и возможности промышленного уровня.
Он предоставляет простой в использовании API, который позволяет создавать модели классификации и анализа тональности, используя самые современные алгоритмы для каждой проблемы.
4. TensorFlow
TensorFlow — это платформа Google с открытым исходным кодом для машинного обучения, которая быстро стала самой популярной библиотекой, используемой такими компаниями, как Twitter, AirBnb и Uber. Благодаря инструментам и ресурсам, которые постоянно обновляются, вы можете начать создавать мощные модели глубокого обучения по мере обучения.
С помощью Tensorflow API (доступного на разных языках программирования) вы можете создавать модели для выполнения расширенных задач классификации текста.
5. PyTorch
PyTorch — это платформа машинного обучения с открытым исходным кодом, основанная на библиотеке Torch и разработанная Facebook. Простой, гибкий и быстрый, он отлично подходит как для разработчиков, так и для исследователей, которые хотят обучать модели глубокого обучения.
Простой, гибкий и быстрый, он отлично подходит как для разработчиков, так и для исследователей, которые хотят обучать модели глубокого обучения.
API PyTorch упрощает создание моделей классификации текста и предлагает различные функции для повышения производительности вашей модели.
6. Keras
Keras — это мощная библиотека Python, предназначенная для создания моделей глубокого обучения, которые могут работать поверх таких сред, как TensorFlow, R и Theano.
Благодаря набору простых в использовании и интуитивно понятных API (плюс обширная документация) эта библиотека является отличным местом для начала работы с классификацией текста и получения отличных результатов.
Заключительное примечание
Инструменты классификации текста помогают упорядочивать данные по темам, настроениям, намерениям и т. д. Они позволяют автоматизировать трудоемкие задачи, такие как пометка входящих электронных писем и маршрутизация обращений в службу поддержки клиентов, и дают ценную информацию о том, что клиенты думают о вашем бизнесе.
Автоматизировать повседневные задачи с классификацией текста проще, чем вы думаете, благодаря библиотекам с открытым исходным кодом и инструментам SaaS, к которым легко получить доступ через API.
С помощью API классификации текста MonkeyLearn вы можете создать пользовательскую модель классификации текста и интегрировать ее в свои собственные приложения всего за несколько минут. Готовы попробовать? Зарегистрируйтесь в MonkeyLearn и сразу начните классифицировать свои данные.
Tobias Geisler Mesevage
28 мая 2020 г.
Узлы классификации — получение узлов классификации — REST API (Azure DevOps Work Item Tracking)
Твиттер LinkedIn Фейсбук Эл. адрес
- Ссылка
- Служба:
- Отслеживание рабочих элементов
- Версия API:
- 6,0
Получает корневые узлы классификации или список узлов классификации для данного списка идентификаторов узлов для данного проекта. Если указан параметр ids, вы получите список узлов классификации для этих идентификаторов. В противном случае вы получите корневые узлы классификации для этого проекта.
Если указан параметр ids, вы получите список узлов классификации для этих идентификаторов. В противном случае вы получите корневые узлы классификации для этого проекта.
GET https://dev.azure.com/{organization}/{project}/_apis/wit/classificationnodes?ids={ids}&api-version=6.0 С необязательными параметрами:
GET https://dev.azure.com/{organization}/{project}/_apis/wit/classificationnodes?ids={ids}&$depth={$depth}&errorPolicy={errorPolicy }&api-version=6.0 Параметры URI
| Имя | В | Обязательно | Тип | Описание |
|---|---|---|---|---|
организация | путь | Истинный |
| Имя организации Azure DevOps. |
проект | путь | Истинный |
| ID проекта или имя проекта |
API-версия | запрос | Истинный |
| Используемая версия API. |
идентификаторы | запрос | Истинный |
| Целочисленные идентификаторы узлов классификации, разделенные запятыми. Это не требуется, если вам нужны корневые узлы. |
$глубина | запрос |
| Глубина детей для извлечения. | |
ошибка | запрос |
| Флаг для обработки ошибок при получении некоторых узлов. Возможные варианты: Fail и Omit. |
 Это должно быть установлено на «6.0», чтобы использовать эту версию API.
Это должно быть установлено на «6.0», чтобы использовать эту версию API.Ответы
| Имя | Тип | Описание |
|---|---|---|
| 200 ОК |
| успешная операция |
Безопасность
oauth3
Тип:
oauth3
Поток:
accessCode
URL авторизации:
https://app.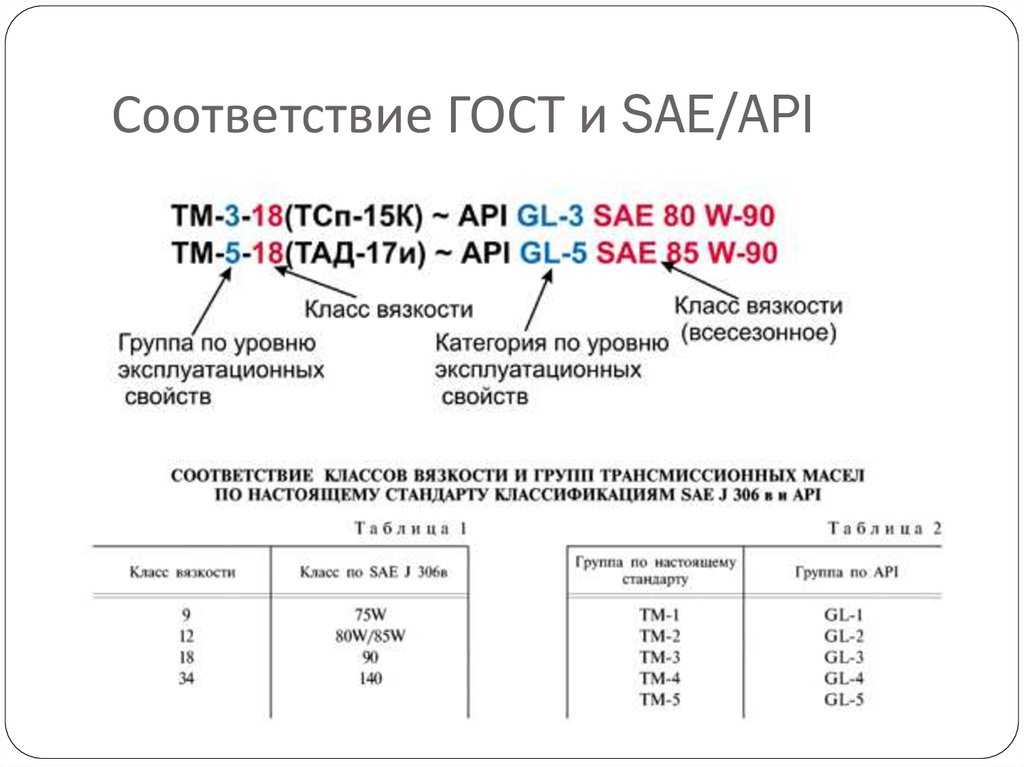 vssps.visualstudio.com/oauth3/authorize&response_type=Assertion
vssps.visualstudio.com/oauth3/authorize&response_type=Assertion
URL токена:
https://app.vssps.visualstudio.com/oauth3/token?client_assertion_type=urn:ietf:params:oauth:client-assertion-type:jwt-bearer&grant_type=urn:ietf:params:oauth:grant-type:jwt- держатель
Прицелы
| Наименование | Описание |
|---|---|
| всо.ворк | Предоставляет возможность чтения рабочих элементов, запросов, досок, путей областей и итераций, а также других метаданных, связанных с отслеживанием рабочих элементов. Также предоставляет возможность выполнять запросы, искать рабочие элементы и получать уведомления о событиях рабочих элементов через служебные перехватчики. |
Примеры
| Получить узлы классификации из списка идентификаторов. |
| Получить узлы классификации с ошибкой |
| Получить дерево областей с 2 уровнями детей |
| Получите дерево итераций с 2 уровнями дочерних элементов |
| Получить дерево корневой области |
| Получить корневое дерево итераций |
Получить узлы классификации из списка идентификаторов.

Образец запроса
- HTTP
ПОЛУЧИТЬ https://dev.azure.com/fabrikam/Fabrikam-Fiber-Git/_apis/wit/classificationnodes?ids=1,3&api-version=6.0
Пример ответа
- Код состояния:
- 200
{
"счет": 2,
"ценность": [
{
"идентификатор": 1,
"идентификатор": "ffba9b15-c8c9-42f8-b2d2-423807d8d3fd",
"имя": "демо",
"структурный тип": "итерация",
"имеет детей": правда,
"путь": "/fabrikam/fiber/tfvc/iteration",
"_ссылки": {
"себя": {
"href": "https://dev.azure.com/fabrikam/52202911-0aa5-4f0a-9371-9ef681b0de74/_apis/wit/classificationNodes/Итерации"
}
},
"url": "https://dev.azure.com/fabrikam/52202911-0aa5-4f0a-9371-9ef681b0de74/_apis/wit/classificationNodes/Iterations"
},
{
"идентификатор": 3,
"идентификатор": "ce814585-1e70-4869-841c-dd0e98118a0c",
"name": "Итерация 1",
"структурный тип": "итерация",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"атрибуты": {
"startDate": "2018-01-15T00:00:00Z",
"finishDate": "2018-01-31T00:00:00Z"
},
"_ссылки": {
"себя": {
"href": "https://dev.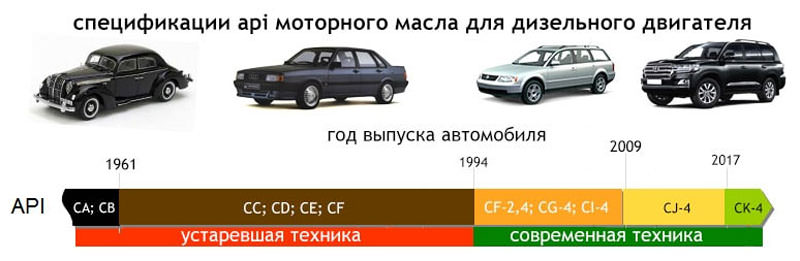 azure.com/fabrikam/52202911-0aa5-4f0a-9371-9ef681b0de74/_apis/wit/classificationNodes/Итерации/Итерация%201"
},
"родитель": {
"href": "https://dev.azure.com/fabrikam/52202911-0aa5-4f0a-9371-9ef681b0de74/_apis/wit/classificationNodes/Iterations"
}
},
"url": "https://dev.azure.com/fabrikam/52202911-0aa5-4f0a-9371-9ef681b0de74/_apis/wit/classificationNodes/Iterations/Iteration%201"
}
]
}
azure.com/fabrikam/52202911-0aa5-4f0a-9371-9ef681b0de74/_apis/wit/classificationNodes/Итерации/Итерация%201"
},
"родитель": {
"href": "https://dev.azure.com/fabrikam/52202911-0aa5-4f0a-9371-9ef681b0de74/_apis/wit/classificationNodes/Iterations"
}
},
"url": "https://dev.azure.com/fabrikam/52202911-0aa5-4f0a-9371-9ef681b0de74/_apis/wit/classificationNodes/Iterations/Iteration%201"
}
]
} Получить узлы классификации с параметром errorPolicy.
Образец запроса
- HTTP
ПОЛУЧИТЬ https://dev.azure.com/fabrikam/Fabrikam-Fiber-Git/_apis/wit/classificationnodes?ids=1,2&api-version=6.0
Пример ответа
- Код состояния:
- 200
{
"счет": 2,
"ценность": [
{
"идентификатор": 1,
"идентификатор": "ffba9b15-c8c9-42f8-b2d2-423807d8d3fd",
"имя": "демо",
"структурный тип": "итерация",
"имеет детей": правда,
"путь": "/fabrikam/fiber/tfvc/iteration",
"_ссылки": {
"себя": {
"href": "https://dev. azure.com/fabrikam/52202911-0aa5-4f0a-9371-9ef681b0de74/_apis/wit/classificationNodes/Итерации"
}
},
"url": "https://dev.azure.com/fabrikam/52202911-0aa5-4f0a-9371-9ef681b0de74/_apis/wit/classificationNodes/Iterations"
},
нулевой
]
}
azure.com/fabrikam/52202911-0aa5-4f0a-9371-9ef681b0de74/_apis/wit/classificationNodes/Итерации"
}
},
"url": "https://dev.azure.com/fabrikam/52202911-0aa5-4f0a-9371-9ef681b0de74/_apis/wit/classificationNodes/Iterations"
},
нулевой
]
} Получить дерево областей с 2 уровнями дочерних элементов
Образец запроса
- HTTP
ПОЛУЧИТЬ https://dev.azure.com/fabrikam/Fabrikam-Fiber-Git/_apis/wit/classificationnodes?$depth=2&api-version=6.0
Пример ответа
- Код состояния:
- 200
{
"идентификатор": 3568,
"идентификатор": "7fc6fce0-105b-403c-a126-8f8212713fd7",
"имя": "Фабрикам-Fiber-Git",
"тип структуры": "площадь",
"имеет детей": правда,
"путь": "/fabrikam/fiber/tfvc/iteration",
"дети": [
{
"идентификатор": 4482,
"идентификатор": "7aebdc2d-3b54-416f-8daf-171b2dd38a7b",
"имя": "Устройства",
"тип структуры": "площадь",
"имеет детей": правда,
"путь": "/fabrikam/fiber/tfvc/iteration",
"дети": [
{
"идентификатор": 4483,
"идентификатор": "c3f3c661-9а81-4925-баа3-а91б36еа77ф4",
"имя": "Windows Phone",
"тип структуры": "площадь",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev. azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas/Devices/Windows%20Phone"
},
{
"идентификатор": 4484,
"идентификатор": "5f00e777-9531-4931-9951-d86e18a95569",
"имя": "Поверхность",
"тип структуры": "площадь",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas/Devices/Surface"
},
{
"идентификатор": 4485,
"идентификатор": "459a3f9f-6200-4343-8fd4-5927e01dbe93",
"имя": "Айфон",
"тип структуры": "площадь",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas/Devices/iPhone"
}
],
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas/Devices"
},
{
"идентификатор": 4486,
"идентификатор": "968dbbb1-b355-4d41-9d55-61ffe87f4699",
"имя": "Веб-сайт",
"тип структуры": "площадь",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev.
azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas/Devices/Windows%20Phone"
},
{
"идентификатор": 4484,
"идентификатор": "5f00e777-9531-4931-9951-d86e18a95569",
"имя": "Поверхность",
"тип структуры": "площадь",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas/Devices/Surface"
},
{
"идентификатор": 4485,
"идентификатор": "459a3f9f-6200-4343-8fd4-5927e01dbe93",
"имя": "Айфон",
"тип структуры": "площадь",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas/Devices/iPhone"
}
],
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas/Devices"
},
{
"идентификатор": 4486,
"идентификатор": "968dbbb1-b355-4d41-9d55-61ffe87f4699",
"имя": "Веб-сайт",
"тип структуры": "площадь",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev.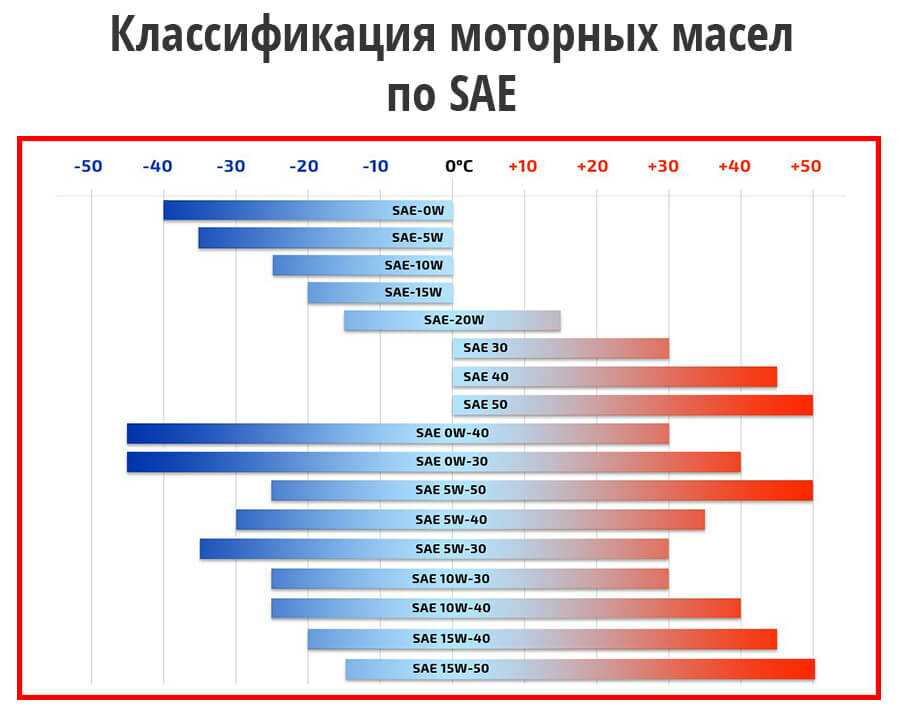 azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas/Веб-сайт"
},
{
"идентификатор": 4487,
"идентификатор": "fb722a2f-ebf6-4c31-959б-334dac1ed31e",
"имя": "Бэкенд",
"тип структуры": "площадь",
"имеет детей": правда,
"путь": "/fabrikam/fiber/tfvc/iteration",
"дети": [
{
"идентификатор": 4488,
"идентификатор": "b8104791-798c-4ae8-a293-e1adbde7c10a",
"имя": "База данных",
"тип структуры": "площадь",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas/Backend/Database"
},
{
"идентификатор": 4489,
"идентификатор": "17115d5c-4c63-4530-80df-df6d42a2864d",
"name": "Средний уровень",
"тип структуры": "площадь",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev.
azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas/Веб-сайт"
},
{
"идентификатор": 4487,
"идентификатор": "fb722a2f-ebf6-4c31-959б-334dac1ed31e",
"имя": "Бэкенд",
"тип структуры": "площадь",
"имеет детей": правда,
"путь": "/fabrikam/fiber/tfvc/iteration",
"дети": [
{
"идентификатор": 4488,
"идентификатор": "b8104791-798c-4ae8-a293-e1adbde7c10a",
"имя": "База данных",
"тип структуры": "площадь",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas/Backend/Database"
},
{
"идентификатор": 4489,
"идентификатор": "17115d5c-4c63-4530-80df-df6d42a2864d",
"name": "Средний уровень",
"тип структуры": "площадь",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev. azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas/Backend/Middle-tier"
}
],
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas/Backend"
}
],
"_ссылки": {
"себя": {
"href": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas"
}
},
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas"
}
azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas/Backend/Middle-tier"
}
],
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas/Backend"
}
],
"_ссылки": {
"себя": {
"href": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas"
}
},
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas"
} Получить дерево итераций с 2 уровнями дочерних элементов
Образец запроса
- HTTP
ПОЛУЧИТЬ https://dev.azure.com/fabrikam/Fabrikam-Fiber-Git/_apis/wit/classificationnodes?$depth=2&api-version=6.0
Пример ответа
- Код состояния:
- 200
{
"идентификатор": 3569,
"идентификатор": "49cea43c-16b2-417c-a98f-65d511e3ca9d",
"имя": "Фабрикам-Fiber-Git",
"структурный тип": "итерация",
"имеет детей": правда,
"путь": "/fabrikam/fiber/tfvc/iteration",
"дети": [
{
"идентификатор": 3566,
"идентификатор": "6b5153a0-76f7-4aad-bd60-7dbfe3c2947d",
"имя": "Релиз 3",
"структурный тип": "итерация",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev.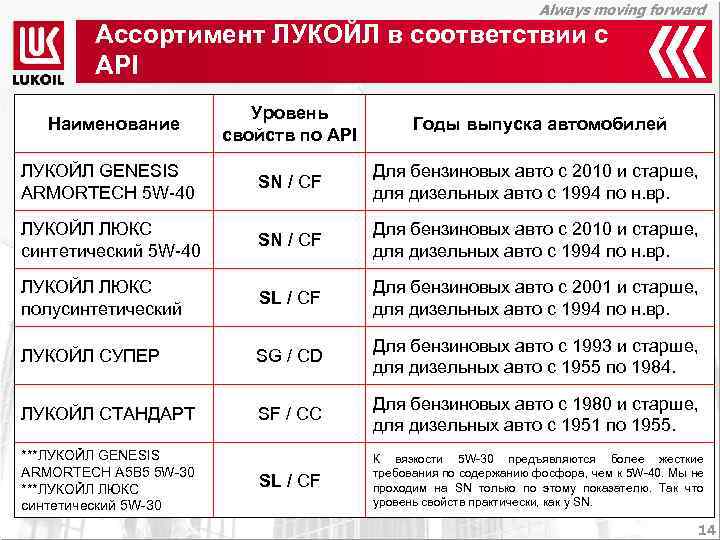 azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%203"
},
{
"идентификатор": 3571,
"идентификатор": "8c80c27e-8afb-4315-9057-686a1b862ed5",
"name": "Релиз 2",
"структурный тип": "итерация",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%202"
},
{
"идентификатор": 3572,
"идентификатор": "92938702-f26f-4f3a-b291-67f84b16c479",
"name": "Релиз 4",
"структурный тип": "итерация",
"путь": "/fabrikam/fiber/tfvc/iteration",
"hasChildren": ложь,
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%204"
},
{
"идентификатор": 3576,
"идентификатор": "395a6b4f-6488-41ee-a06a-1514405ab6f0",
"имя": "Релиз 1",
"структурный тип": "итерация",
"имеет детей": правда,
"путь": "/fabrikam/fiber/tfvc/iteration",
"дети": [
{
"идентификатор": 3564,
"идентификатор": "63d12e9д-37фд-48аф-80а5-б93095705806",
"name": "Спринт 4",
"структурный тип": "итерация",
"hasChildren": ложь,
"url": "https://dev.
azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%203"
},
{
"идентификатор": 3571,
"идентификатор": "8c80c27e-8afb-4315-9057-686a1b862ed5",
"name": "Релиз 2",
"структурный тип": "итерация",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%202"
},
{
"идентификатор": 3572,
"идентификатор": "92938702-f26f-4f3a-b291-67f84b16c479",
"name": "Релиз 4",
"структурный тип": "итерация",
"путь": "/fabrikam/fiber/tfvc/iteration",
"hasChildren": ложь,
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%204"
},
{
"идентификатор": 3576,
"идентификатор": "395a6b4f-6488-41ee-a06a-1514405ab6f0",
"имя": "Релиз 1",
"структурный тип": "итерация",
"имеет детей": правда,
"путь": "/fabrikam/fiber/tfvc/iteration",
"дети": [
{
"идентификатор": 3564,
"идентификатор": "63d12e9д-37фд-48аф-80а5-б93095705806",
"name": "Спринт 4",
"структурный тип": "итерация",
"hasChildren": ложь,
"url": "https://dev. azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%201/Sprint%204"
},
{
"идентификатор": 3565,
"идентификатор": "c9206006-4362-4b16-9205-1b94d32a6fb2",
"name": "Спринт 2",
"структурный тип": "итерация",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"атрибуты": {
"startDate": "2014-03-17T00:00:00Z",
"finishDate": "2014-03-28T00:00:00Z"
},
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%201/Sprint%202"
},
{
"идентификатор": 3567,
"идентификатор": "ae109273-2806-42b8-8c41-d249c7253760",
"name": "Спринт 6",
"структурный тип": "итерация",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%201/Sprint%206"
},
{
"идентификатор": 3573,
"идентификатор": "9fd05e41-9dc2-40b0-b826-d7dd0ab3dc24",
"name": "Спринт 5",
"структурный тип": "итерация",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev.
azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%201/Sprint%204"
},
{
"идентификатор": 3565,
"идентификатор": "c9206006-4362-4b16-9205-1b94d32a6fb2",
"name": "Спринт 2",
"структурный тип": "итерация",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"атрибуты": {
"startDate": "2014-03-17T00:00:00Z",
"finishDate": "2014-03-28T00:00:00Z"
},
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%201/Sprint%202"
},
{
"идентификатор": 3567,
"идентификатор": "ae109273-2806-42b8-8c41-d249c7253760",
"name": "Спринт 6",
"структурный тип": "итерация",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%201/Sprint%206"
},
{
"идентификатор": 3573,
"идентификатор": "9fd05e41-9dc2-40b0-b826-d7dd0ab3dc24",
"name": "Спринт 5",
"структурный тип": "итерация",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev. azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%201/Sprint%205"
},
{
"идентификатор": 3574,
"идентификатор": "eb2bdabd-0c3c-4f55-adcc-106dcedd8528",
"name": "Спринт 1",
"структурный тип": "итерация",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"атрибуты": {
"startDate": "2014-03-03T00:00:00Z",
"finishDate": "2014-03-14T00:00:00Z"
},
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%201/Sprint%201"
},
{
"идентификатор": 3575,
"идентификатор": "5b96a849-05c3-4685-bbf6-d33cc1becd6a",
"name": "Спринт 3",
"структурный тип": "итерация",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%201/Sprint%203"
}
],
"url": "https://dev.
azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%201/Sprint%205"
},
{
"идентификатор": 3574,
"идентификатор": "eb2bdabd-0c3c-4f55-adcc-106dcedd8528",
"name": "Спринт 1",
"структурный тип": "итерация",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"атрибуты": {
"startDate": "2014-03-03T00:00:00Z",
"finishDate": "2014-03-14T00:00:00Z"
},
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%201/Sprint%201"
},
{
"идентификатор": 3575,
"идентификатор": "5b96a849-05c3-4685-bbf6-d33cc1becd6a",
"name": "Спринт 3",
"структурный тип": "итерация",
"hasChildren": ложь,
"путь": "/fabrikam/fiber/tfvc/iteration",
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%201/Sprint%203"
}
],
"url": "https://dev. azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%201"
}
],
"_ссылки": {
"себя": {
"href": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations"
}
},
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations"
}
azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations/Release%201"
}
],
"_ссылки": {
"себя": {
"href": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations"
}
},
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations"
} Получить дерево корневой области
Образец запроса
- HTTP
ПОЛУЧИТЬ https://dev.azure.com/fabrikam/Fabrikam-Fiber-Git/_apis/wit/classificationnodes?api-version=6.0
Пример ответа
- Код состояния:
- 200
{
"идентификатор": 3568,
"идентификатор": "2e5e8ec1-40d1-4da1-bcca-49949b2e5607",
"имя": "Фабрикам-Fiber-Git",
"тип структуры": "площадь",
"имеет детей": правда,
"путь": "/fabrikam/fiber/tfvc/iteration",
"_ссылки": {
"себя": {
"href": "https://dev. azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas"
}
},
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas"
}
azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas"
}
},
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Areas"
} Получить корневое дерево итераций
Образец запроса
- HTTP
ПОЛУЧИТЬ https://dev.azure.com/fabrikam/Fabrikam-Fiber-Git/_apis/wit/classificationnodes?api-version=6.0
Пример ответа
- Код состояния:
- 200
{
"идентификатор": 3569,
"идентификатор": "bfd21f76-1329-4ef8-b26d-ccc2d4f",
"имя": "Фабрикам-Fiber-Git",
"структурный тип": "итерация",
"имеет детей": правда,
"путь": "/fabrikam/fiber/tfvc/iteration",
"_ссылки": {
"себя": {
"href": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Итерации"
}
},
"url": "https://dev.azure.com/fabrikam/6ce954b1-ce1f-45d1-b94d-e6bf2464ba2c/_apis/wit/classificationNodes/Iterations"
} Определения
Классификация Узлы Ошибка Политика Флаг для обработки ошибок при получении некоторых узлов. Возможные варианты: Fail и Omit.
Возможные варианты: Fail и Omit.
Ссылка Ссылка Класс для представления набора ссылок REST.
Дерево Узел Структура Тип Тип структуры узла.
Работа Элемент Классификация Узел Определяет узел классификации для отслеживания рабочих элементов.
ClassificationNodesErrorPolicy
Флаг для обработки ошибок при получении некоторых узлов. Возможные варианты: Fail и Omit.
Имя Тип Описание потерпеть неудачу - нить
пропускать - нить
ReferenceLinks
Класс для представления набора ссылок REST.
Имя Тип Описание ссылки - объект
Вид ссылок только для чтения.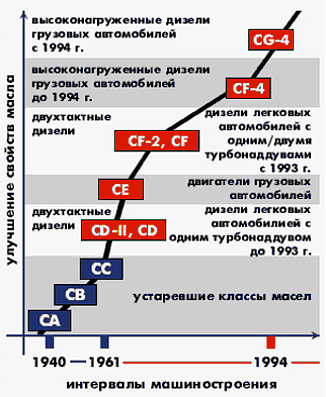 Поскольку справочные ссылки доступны только для чтения, мы хотим сделать их доступными только для чтения.
Поскольку справочные ссылки доступны только для чтения, мы хотим сделать их доступными только для чтения.
TreeNodeStructureType
Тип структуры узла.
Имя Тип Описание область - нить
Тип области.
итерация - нить
Тип итерации.
WorkItemClassificationNode
Определяет узел классификации для отслеживания рабочих элементов.
Имя Тип Описание _ссылки - Ссылка
Ссылка
Ссылки на связанные ресурсы REST.
атрибуты - объект
Словарь с атрибутами узла, такими как дата начала/окончания для узлов итерации.
дети - Работа
Товар Классификация Узел []
Получен список дочерних узлов.
имеет детей - логический
Флаг, указывающий, есть ли у узла классификации какие-либо дочерние узлы.
я бы - целое число
Целочисленный идентификатор узла классификации.
идентификатор - нить
GUID ID узла классификации.
имя - нить
Имя узла классификации.
дорожка - нить
Путь узла классификации.
тип структуры - Дерево
Узел Структура Тип
Тип структуры узла.
URL - нить
Что такое API: определение, спецификации, типы, документация
Время чтения: 12 минут
Если вы когда-либо читали технические журналы или блоги, вы, вероятно, видели аббревиатуру API. Звучит солидно, но что это значит и зачем вам заморачиваться?
Звучит солидно, но что это значит и зачем вам заморачиваться?
Начнем с простого примера: человеческое общение. Мы можем выражать свои мысли, потребности и идеи с помощью языка (письменного и устного), жестов или мимики. Для взаимодействия с компьютерами, приложениями и веб-сайтами требуются компоненты пользовательского интерфейса — экран с меню и графическими элементами, клавиатура и мышь.
Программное обеспечение или его элементы не нуждаются в графическом пользовательском интерфейсе для взаимодействия друг с другом. Программные продукты обмениваются данными и функциями через машиночитаемые интерфейсы — API (интерфейсы прикладного программирования).
Вы также можете посмотреть наше видео с объяснением API
Что такое API?
API — это набор программного кода, который обеспечивает передачу данных между одним программным продуктом и другим. Он также содержит условия этого обмена данными.
Как работает API.
Интерфейсы прикладного программирования состоят из двух компонентов:
- Техническая спецификация, описывающая варианты обмена данными между решениями со спецификацией, выполненной в виде запроса протоколов обработки и доставки данных
- Программный интерфейс, написанный в соответствии со спецификацией, которая его представляет
Программное обеспечение, которому требуется доступ к информации (т. е. X стоимости гостиничных номеров на определенные даты) или функциональным возможностям (т. е. маршрут из точки А в точку Б на карте в зависимости от местоположения пользователя) из другого программного обеспечения, вызывает его API, в то время как определение требований к тому, как должны предоставляться данные/функциональность. Другое программное обеспечение возвращает данные/функции, запрошенные предыдущим приложением.
И интерфейс, с помощью которого эти два приложения взаимодействуют, определяется API.
Специалисты Red Hat отмечают, что API-интерфейсы иногда считаются контрактами, где документация является соглашением между сторонами: «Если сторона сначала отправляет удаленный запрос, структурированный определенным образом, именно так будет отвечать программное обеспечение второй стороны». Документация по API — это руководство для разработчиков, включающее всю необходимую информацию о том, как работать с API и использовать предоставляемые им сервисы. Подробнее о документации мы поговорим в одном из следующих разделов.
Документация по API — это руководство для разработчиков, включающее всю необходимую информацию о том, как работать с API и использовать предоставляемые им сервисы. Подробнее о документации мы поговорим в одном из следующих разделов.
Каждый API содержит и реализуется вызовами функций — операторами языка, которые запрашивают программное обеспечение для выполнения определенных действий и услуг. Вызовы функций — это фразы, состоящие из глаголов и существительных, например:
- Начало или завершение сеанса
- Получите удобства для одноместного номера типа
- Восстановление или получение объектов с сервера.
Вызовы функций описаны в документации API.
API служат многим целям. Как правило, они могут упростить и ускорить разработку программного обеспечения. Разработчики могут добавлять функциональные возможности (например, рекомендательный механизм, бронирование жилья, распознавание изображений, обработку платежей) от других поставщиков к существующим решениям или создавать новые приложения с использованием услуг сторонних поставщиков. Во всех этих случаях специалистам не приходится разбираться с исходным кодом, пытаясь понять, как работает другое решение. Они просто подключают свое программное обеспечение к другому. Другими словами, API служат слоем абстракции между двумя системами, скрывая сложность и рабочие детали последней.
Во всех этих случаях специалистам не приходится разбираться с исходным кодом, пытаясь понять, как работает другое решение. Они просто подключают свое программное обеспечение к другому. Другими словами, API служат слоем абстракции между двумя системами, скрывая сложность и рабочие детали последней.
Типы API-интерфейсов
API-интерфейсы по доступности, также известные как политики выпуска
С точки зрения политик выпуска API-интерфейсы могут быть частными, партнерскими и общедоступными.
Типы API по доступности
Частные API. Эти интерфейсы прикладного программного обеспечения предназначены для улучшения решений и услуг в рамках организации. Собственные разработчики или подрядчики могут использовать эти API для интеграции ИТ-систем или приложений компании, создания новых систем или клиентских приложений с использованием существующих систем. Даже если приложения общедоступны, сам интерфейс остается доступным только для тех, кто работает напрямую с издателем API. Приватная стратегия позволяет компании полностью контролировать использование API.
Приватная стратегия позволяет компании полностью контролировать использование API.
Партнерские API. Партнерские API открыто рекламируются, но передаются бизнес-партнерам, подписавшим соглашение с издателем. Обычный вариант использования партнерских API — это интеграция программного обеспечения между двумя сторонами. Компания, предоставляющая партнерам доступ к данным или возможностям, получает дополнительный доход. В то же время он может отслеживать, как используются открытые цифровые активы, гарантировать, что сторонние решения, использующие их API, обеспечивают достойное взаимодействие с пользователем, и поддерживать фирменный стиль в своих приложениях.
Общедоступные API. Эти API, также известные как внешние или предназначенные для разработчиков, доступны для любых сторонних разработчиков. Публичная программа API позволяет повысить узнаваемость бренда и получить дополнительный источник дохода при правильном выполнении.
Существует два типа общедоступных API — открытые (бесплатные) и коммерческие. Определение Open API предполагает, что все функции такого API являются общедоступными и могут использоваться без ограничительных условий. Например, можно создать приложение, использующее API, без явного одобрения поставщика API или обязательных лицензионных сборов. В определении также говорится, что описание API и любая связанная с ним документация должны быть в открытом доступе и что API можно свободно использовать для создания и тестирования приложений.
Определение Open API предполагает, что все функции такого API являются общедоступными и могут использоваться без ограничительных условий. Например, можно создать приложение, использующее API, без явного одобрения поставщика API или обязательных лицензионных сборов. В определении также говорится, что описание API и любая связанная с ним документация должны быть в открытом доступе и что API можно свободно использовать для создания и тестирования приложений.
Пользователи коммерческих API оплачивают подписку или используют API на основе оплаты по мере использования. Популярный подход среди издателей — предлагать бесплатные пробные версии, чтобы пользователи могли оценить API перед покупкой подписки. Узнайте больше о том, какую пользу предприятиям принесет открытие своих API для общего пользования, в нашей подробной статье об экономике API.
API по вариантам использования
API можно классифицировать в соответствии с системами, для которых они разработаны.
API баз данных. API базы данных обеспечивают связь между приложением и системой управления базой данных. Разработчики работают с базами данных, создавая запросы для доступа к данным, изменения таблиц и т. д. Например, Drupal 7 Database API позволяет пользователям писать унифицированные запросы для различных баз данных, как собственных, так и открытых (Oracle, MongoDB, PostgreSQL, MySQL, CouchDB). и MSSQL).
API базы данных обеспечивают связь между приложением и системой управления базой данных. Разработчики работают с базами данных, создавая запросы для доступа к данным, изменения таблиц и т. д. Например, Drupal 7 Database API позволяет пользователям писать унифицированные запросы для различных баз данных, как собственных, так и открытых (Oracle, MongoDB, PostgreSQL, MySQL, CouchDB). и MSSQL).
Другой пример — API базы данных ORDS, встроенный в Oracle REST Data Services.
API операционных систем. Эта группа API определяет, как приложения используют ресурсы и службы операционных систем. Каждая ОС имеет свой набор API, например, Windows API или Linux API (API пространства пользователя ядра и внутренний API ядра).
Apple предоставляет справочник по API для macOS и iOS в своей документации для разработчиков. API-интерфейсы для создания приложений для настольной операционной системы Apple macOS включены в набор инструментов разработчика Cocoa. Те, кто создает приложения для мобильной операционной системы iOS, используют Cocoa Touch — модифицированную версию Cocoa.
Те, кто создает приложения для мобильной операционной системы iOS, используют Cocoa Touch — модифицированную версию Cocoa.
Удаленные API. Удаленные API определяют стандарты взаимодействия для приложений, работающих на разных компьютерах. Другими словами, один программный продукт обращается к ресурсам, расположенным за пределами запрашивающего их устройства, что и объясняет название. Поскольку два удаленно расположенных приложения связаны через коммуникационную сеть, в частности через Интернет, большинство удаленных API написаны на основе веб-стандартов. API подключения к базе данных Java и API вызова удаленного метода Java — два примера интерфейсов удаленного программирования приложений.
Веб-API. Этот класс API является наиболее распространенным. Веб-API обеспечивают машиночитаемые данные и передачу функций между веб-системами, представляющими архитектуру клиент-сервер. Эти API в основном доставляют запросы от веб-приложений и ответы от серверов с использованием протокола передачи гипертекста (HTTP).
Разработчики могут использовать веб-API для расширения функциональности своих приложений или сайтов. Например, API Pinterest поставляется с инструментами для добавления данных пользователей Pinterest, таких как доски или пины, на веб-сайт. Google Maps API позволяет добавлять карту с указанием местонахождения организации.
Большинство предприятий используют более одного API для подключения приложений и обмена информацией. Некоторым в конечном итоге требуется инструмент управления API, который поможет им контролировать, распространять и анализировать различные API. Узнайте больше об управлении API в нашей подробной статье.
Спецификации/протоколы API
Целью спецификаций API является стандартизация обмена данными между веб-сервисами. В данном случае стандартизация означает способность различных систем, написанных на разных языках программирования и/или работающих на разных ОС или использующих разные технологии, беспрепятственно взаимодействовать друг с другом.
Существует несколько спецификаций API
Удаленный вызов процедур (RPC)
Веб-API могут придерживаться принципов обмена ресурсами, основанных на удаленном вызове процедур. Этот протокол определяет взаимодействие между клиент-серверными приложениями. Одна программа (клиент) запрашивает данные или функции у другой программы (сервера), расположенной на другом компьютере в сети, и сервер отправляет требуемый ответ.
RPC также известен как вызов подпрограммы или функции. Одним из двух способов реализации удаленного вызова процедур является SOAP.
Протокол доступа к служебным объектам (SOAP)
SOAP — это упрощенный протокол для обмена структурированной информацией в децентрализованной распределенной среде, в соответствии с определением, разработанным корпорацией Майкрософт. Вообще говоря, эта спецификация содержит правила синтаксиса для сообщений запросов и ответов, отправляемых веб-приложениями. API-интерфейсы, соответствующие принципам SOAP, позволяют обмениваться XML-сообщениями между системами через HTTP или SMTP для передачи почты.
Расширяемый язык разметки (XML) — это простой и очень гибкий текстовый формат, широко используемый для хранения данных и обмена ими через Интернет или другие сети. XML определяет набор правил для кодирования документов в формате, который могут читать как люди, так и машины. Язык разметки представляет собой набор символов, которые можно размещать в тексте для обозначения и обозначения частей текстового документа. Текстовые XML-документы содержат самоописывающие теги объектов данных, что делает их легко читаемыми.
Пример вызова XML-запроса SOAP в Google Ad Manager. Источник: Google Ad Manager
SOAP в основном используется с корпоративным веб-приложением для обеспечения высокой безопасности передаваемых данных. API-интерфейсы SOAP предпочитают поставщики платежных шлюзов, решений для управления идентификацией и CRM, а также финансовых и телекоммуникационных услуг. Общедоступный API PayPal — один из широко известных API SOAP. Он также часто используется для поддержки устаревших систем.
Он также часто используется для поддержки устаревших систем.
Передача репрезентативного состояния (REST)
Термин REST был введен компьютерным специалистом Роем Филдингом в диссертации в 2000 году. В отличие от SOAP, который является протоколом, REST представляет собой стиль архитектуры программного обеспечения с шестью ограничениями для создания работающих приложений. через HTTP, часто веб-сервисы. Всемирная паутина является наиболее распространенной реализацией и применением этого архитектурного стиля.
REST считается более простой альтернативой SOAP, который многим разработчикам сложно использовать, поскольку он требует написания большого количества кода для выполнения каждой задачи и следования структуре XML для каждого отправляемого сообщения. REST следует другой логике, поскольку он делает данные доступными в качестве ресурсов. Каждый ресурс представлен уникальным URL-адресом, и можно запросить этот ресурс, указав его URL-адрес.
Веб-API, соответствующие архитектурным ограничениям REST, называются RESTful API. Эти API используют HTTP-запросы (методы или глаголы AKA) для работы с ресурсами: GET, PUT, HEAD, POST, PATCH, CONNECT, TRACE, OPTIONS и DELETE.
Эти API используют HTTP-запросы (методы или глаголы AKA) для работы с ресурсами: GET, PUT, HEAD, POST, PATCH, CONNECT, TRACE, OPTIONS и DELETE.
Системы RESTful поддерживают обмен сообщениями в различных форматах, таких как обычный текст, HTML, YAML, XML и JSON, в то время как SOAP поддерживает только XML. Возможность поддерживать несколько форматов для хранения и обмена данными — одна из причин, по которой REST в наши дни является преобладающим выбором для создания общедоступных API.
Гиганты социальных сетей и туристические компании предоставляют внешние API, чтобы еще больше повысить узнаваемость своего бренда. Twitter имеет множество RESTful API; Expedia предлагает своим партнерам как SOAP, так и RESTful API. Если вы планируете изменить свое предложение для бизнеса в сфере туризма и гостеприимства, погрузитесь в мир API для путешествий и бронирования с помощью нашей специальной статьи.
Обозначение объектов JavaScript (JSON) — это легкий и удобный для анализа текстовый формат для обмена данными. Его синтаксис основан на подмножестве стандарта ECMA-262 3rd Edition. Каждый файл JSON содержит коллекции пар имя/значение и упорядоченные списки значений. Поскольку это универсальные структуры данных, формат можно использовать с любым языком программирования.
Его синтаксис основан на подмножестве стандарта ECMA-262 3rd Edition. Каждый файл JSON содержит коллекции пар имя/значение и упорядоченные списки значений. Поскольку это универсальные структуры данных, формат можно использовать с любым языком программирования.
GET-запрос сведений о ресторане с ответом в формате JSON. Источник: OpenTable
JSON получил широкое распространение благодаря популярности REST.
gRPC
gRPC — это универсальная платформа API с открытым исходным кодом, которая также классифицируется как RPC. В отличие от SOAP, gRPC намного новее и был публично выпущен Google в 2015 году. С gRPC клиентское приложение может напрямую вызывать методы из серверного приложения, расположенного на другом компьютере, как если бы это был локальный объект. Это упрощает создание распределенных сервисов и приложений.
Подобно SOAP и REST, транспортным уровнем для gRPC является HTTP. Однако, подобно RCP, gRPC позволяет разработчикам определять любые виды вызовов функций, а не выбирать из предопределенных параметров, таких как PUT и GET в случае REST.
По умолчанию gRPC использует буферы протокола вместо JSON или XML в качестве языка определения интерфейса (IDL) для сериализации структурированных данных. Здесь разработчик должен сначала определить структуру данных, которые он хочет сериализовать. Как только структуры данных определены, они используют компилятор буфера протокола для генерации классов доступа к данным на выбранном вами языке программирования. Затем данные сжимаются и сериализуются в двоичном формате во время выполнения. Узнайте больше о gRPC в нашей подробной статье.
Пример параметров метода RPC и типов возвращаемых значений. Источник: gRCP
gRPC в основном используется для связи между микросервисами, поскольку он доступен на нескольких языках и обладает высокой производительностью.
GraphQL
Потребность в более быстрой разработке функций, более эффективной загрузке данных из-за более широкого внедрения мобильных устройств и множестве клиентов заставила разработчиков искать другие подходы к архитектуре программного обеспечения. GraphQL, первоначально созданный Facebook в 2012 году для внутреннего использования, представляет собой новый REST с такими организациями, как Shopify, Yelp, GitHub, Coursera и 9.0871 The New York Times использует его для создания API.
GraphQL, первоначально созданный Facebook в 2012 году для внутреннего использования, представляет собой новый REST с такими организациями, как Shopify, Yelp, GitHub, Coursera и 9.0871 The New York Times использует его для создания API.
GraphQL — это язык запросов для API. Это позволяет клиенту детализировать точные данные, которые ему нужны, и упрощает агрегирование данных из нескольких источников, поэтому разработчик может использовать один вызов API для запроса всех необходимых данных. Еще одна особенность GraphQL заключается в том, что для описания данных он использует систему типов .
Использование типов для описания данных позволяет приложениям указывать, какие данные им необходимо получить
Приложения, использующие GraphQL, контролируют, какие данные им нужно получать с сервера, что позволяет им работать быстро, даже когда мобильное соединение медленное. Вы можете увидеть, как GraphQL, REST, RPC и SOAP сравниваются в связанной статье.
Документация API
Сколько бы возможностей для создания или расширения программных продуктов не давало API, оно так и осталось бы непригодным куском кода, если бы разработчики не понимали, как с ним работать. Хорошо написанная и структурированная документация по API, объясняющая, как эффективно использовать и интегрировать API в простой для понимания форме, порадует разработчика и поможет рекомендовать API коллегам.
Документация по API — это справочное руководство со всей необходимой информацией об API, включая функции, классы, типы возвращаемых значений и аргументы.
Многочисленные элементы контента составляют хорошую документацию, например:
- краткое руководство
- аутентификационная информация
- объяснений для каждого вызова API (запроса)
- примеров каждого запроса и возврата с описанием ответа, сообщениями об ошибках и т. д.
- примеров кода для популярных языков программирования, таких как Python, Java, JavaScript или PHP;
- учебники
- Примеры SDK (если SDK доступны), иллюстрирующие, как получить доступ к ресурсу и т.
 д.
д.
Документация может быть статической и интерактивной. Последний позволяет опробовать API и просмотреть возвращаемые результаты и обычно состоит из двух столбцов: человеческий и машинный. Колонка «человек» содержит описания API, а «машина» имеет консоль для совершения вызовов и содержит информацию, которая будет интересна клиентам и серверам при тестировании API.
Столбцы «люди» и «машины» в документации Примеры кода в столбце «машина» (справа) после того, как пользователь щелкнул для действия («Получить всех сотрудников»). Источник: AMIS
Генерация — это процесс документирования API разработчиками и техническими писателями. Специалисты могут использовать решения для документации API (например, инструменты Swagger, Postman, Slate или ReDoc) для унификации структуры и дизайна документации.
Примеры API
Вот несколько примеров хорошо известных API, которые используют разные протоколы и спецификации. Проверьте их документацию, чтобы получить дополнительную информацию и ссылки.
Проверьте их документацию, чтобы получить дополнительную информацию и ссылки.
Карты Google. Не секрет, что Google входит в число технологических гигантов и устанавливает стандарты работы других компаний. Большинство веб-сайтов со встроенной картой используют API Карт Google. Например, Google Directions API использует HTTP-запрос для возврата маршрутов в формате XML или JSON между геолокациями.
Вулкан. Vulkan — это кроссплатформенный API, работающий на уровне операционной системы. Он позволяет разработчикам создавать высококачественную графику в реальном времени в приложениях и обеспечивает связь между приложением и графическим процессором. Ознакомьтесь с документацией по Vulkan API, если вам интересно.
Поиск рейсов Skyscanner. Skyscanner — это платформа метапоиска, которая позволяет путешественникам искать авиабилеты по лучшим ценам в базе данных цен Skyscanner. Кроме того, Skyscanner предоставляет своим аффилированным партнерам RESTful API, поддерживающий как XML, так и JSON в качестве форматов обмена данными. В целях повышения безопасности они рекомендуют партнерам использовать для запросов только протокол HTTPS. Вы можете проверить их документацию здесь.
В целях повышения безопасности они рекомендуют партнерам использовать для запросов только протокол HTTPS. Вы можете проверить их документацию здесь.
API погоды. Это бесплатный поставщик информации о геолокации и погоде с множеством различных API, начиная от прогноза погоды, поиска IP-адресов, спорта, астрономии, геолокации и часового пояса. Он предоставляет доступ к геоданным и погоде с помощью JSON/XML RESTful API. Разработчики могут использовать HTTP или HTTPS для запроса API. Они предоставляют разработчикам подробную документацию о том, как использовать все свои API.
Доступность Sabre Air. Это Sabre SOAP API, используемый для поиска рейсов и соответствующей информации о доступности для заданных дат, пунктов отправления и назначения. Поскольку это SOAP API, он использует XML в качестве формата обмена данными и протоколы HTTP или HTTPS для запросов.
API Yelp. Это GraphQL API, который предоставляет пользователям рекомендации и обзоры лучших ресторанов, развлечений, ночных клубов и многого другого.
Наверх